Hva er SPC?
- Analyse av tidsrekker/tidsserieanalyse som krever relativt lite data for å komme til sikre konklusjoner
- Et sett med metoder for vedvarende forbedring av systemer, prosesser og resultater
- Rammeverk som passer bra for registerdata, følger de samme målene over tid og viser om de utvikler seg
- Godt egnet for forbedringsarbeid
I analyser med SPC, deles variasjon opp i naturlig og spesiell:
- Naturlig variasjon er en iboende egenskap ved prosessen. Variasjonen skyldes tilfeldigheter og inneholder ingen systematikk, men reflekterer prosessens rytme. Eksempel: kroppstemperaturen til en frisk person varierer naturlig mellom 36.5 og 37.5 grader
- Spesiell variasjon har andre årsaker som ikke er iboende i prosessen. Eksempel: kroppstemperatur ved feber. Det er denne type variasjon vi er ute etter å avdekke.
En prosess regnes som stabil når den kun utviser naturlig variasjon. Det motsatte er en prosess som er “ute av kontroll”, eller ustabil, fordi den har spesiell variasjon.
Vi har to typer diagrammer for å oppdage spesiell variasjon: run-diagram og kontrolldiagram. Både run-diagram og kontroll-diagram har som formål å vise nivå på prosessen samt å skille naturlig variasjon fra spesiell variasjon i dataene som kommer ut av en prosess.
- Kan plotte alle typer data
- Antar ingen fordeling
- Plott av målingene over tid, med median som senterlinje. Hvis målingene kommer fra ulike individer, plottes de i rekkefølgen de ble samlet inn i og trekker en linje fra punkt til punkt.
- Minimum 15 datapunkter + de som evt. havner på medianen. Dette for å ha tilstrekkelig statistisk styrke til å identifisere en spesiell variasjon. Antall utover 24 punkter gir ikke ytterligere statistisk styrke.
- Et run er ett eller flere etterfølgende punkter på samme side av medianen (punkter på medianen regnes ikke med)
- Kan avsløre mange, men ikke alle, spesielle variasjoner
Tester for spesiell variasjon
- Test 1 - Mange eller få runs: hva som er mange eller få bestemmes fra tabell. Spesielt mange runs betyr at verdiene hopper mer på tvers av medianen enn forventet. Spesielt få runs betyr at verdiene «klumper» seg sammen på samme side av medianen. Begge deler kan tyde på at det finnes systematikk i dataene. For eksempel kan sesongvariasjoner gjenspeiles i få “runs”.
| Antall observasjoner (ekskludert punkter på medianen ) | Nedre grense for antall runs | Øvre grense for antall runs |
| 14 | 4 | 11 |
| 15 | 4 | 12 |
| 16 | 5 | 12 |
| 17 | 5 | 13 |
| 18 | 6 | 13 |
| 19 | 6 | 14 |
| 20 | 6 | 15 |
| 21 | 7 | 15 |
| 22 | 7 | 16 |
| 23 | 8 | 16 |
| 24 | 8 | 17 |
| 25 | 9 | 17 |
| 26 | 9 | 18 |
| 27 | 9 | 19 |
| 28 | 10 | 19 |
| 29 | 10 | 20 |
| 30 | 10 | 21 |
- Test 2 - Skifte i prosessen: Mange punkter etter hverandre på samme side av senterlinjen. Mange defineres som 8 eller flere hvis vi har 20 datapunkter eller mer, 7 hvis vi har færre enn 20 datapunkter.
- Test 3 - Trend: sammenhengende serie på minst 6-7 punkter (uenighet) av økende eller synkende verdier. Like verdier teller som ett punkt.
Hvis man har utført en intervensjon kan man lage et run-diagram for perioden før og etter intervensjonen i samme figur. De to periodene har hver sin senterlinje. Da får man en indikasjon på om gruppenivået har endret seg betydelig etter intervensjonen (se figur 5).
Eksempel:
Figur 1 viser tid fra første medisinske kontakt (ambulanse ankommer pasienten) til EKG er tatt for 25 pasienter. Hvert punkt representerer en pasient. Median tid til EKG er tatt for disse pasientene er 7 minutter (rød linje). Lengste “run” i denne figuren (test 2) inneholder 6 punkter (pasient 2-7) og det er ingen trend (test 3) i denne figuren. Figuren viser kun naturlig variasjon.
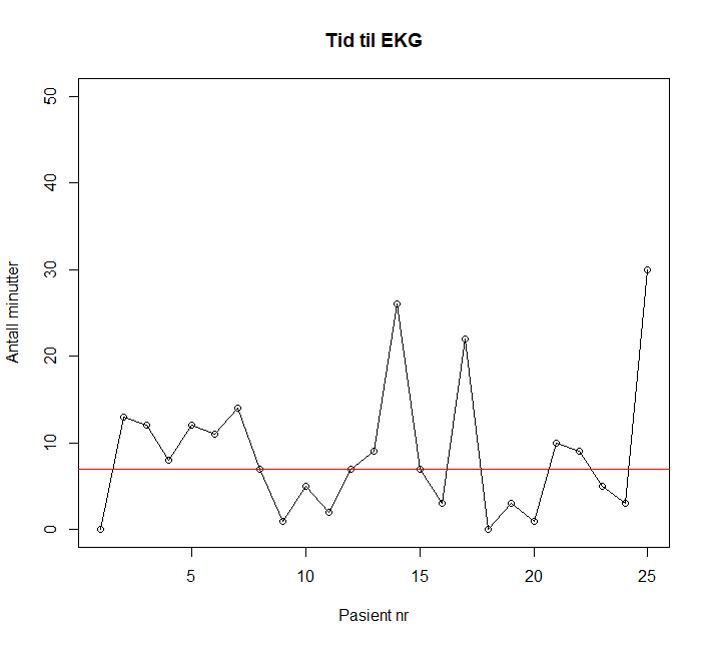
- Antall datapunkter i et kontrolldiagram bør være 20-30. Hvis man har færre enn 20 datapunkter, er det større fare for ikke å få med spesielle variasjoner (type-II-feil/falske negative). Med mer enn 30 datapunkter er det økt fare for å finne spesiell variasjon pga tilfeldigheter (type-I-feil/falske positive).
- Senterlinjen i figuren er gjennomsnittsverdien av datapunktene.
- Benytter kontrollgrenser som er +/- 3 standardavvik fra snittet. Med normalfordelte data tilsvarer dette en p-verdi på 0.0027. p-verdien vil være lav også med andre fordelinger. (Det finnes en oppfatning om at data må være normalfordelte, men normalfordeling er ikke avgjørende for å bruke kontrollgrensene.)
- Mer sensitive og kraftfulle enn run-diagram. Den økte sensitiviteten og kraften i kontroll-diagram ligger i at man bruker øvre og nedre kontrollgrense. Ved dette kan man, hvis ingen spesiell variasjon foreligger, estimere den fremtidige kapasiteten av prosessen ut fra gjennomsnittet og kontrollgrensene. Kontroll-diagram vil også gi mulighet til å estimere yteevnen (kapabiliteten) av en stabil prosess, dvs å kunne forutsi hvilke grenser den stabile prosessen vil holde seg innenfor.
- Grensen på 3 standardavvik er en konvensjon, og kunne vært noe annet. Den er satt mye lavere enn «vanlig» hypotesetesting sin grense på 0.05, blant annet fordi det gjøres så mange tester (hvert punkt er en «test»). Med 25 punkter og kontrollgrenser på 3 sigma/p<0.0027 er sannsynligheten for minst én falsk positiv på 6.5 %. Tilsvarende for kontrollgrenser på 1.96 sigma/p<0.05 er 72 % (disse tallene antar normalfordeling).
- Det vil alltid være en balansegang mellom de to typene feil man kan gjøre, type-I- og type-II-feil. Vanligvis ønsker en å være litt konservativ, og ser det som et større problem å påstå spesiell variasjon der det kun finnes naturlig, enn å gå glipp av et tilfelle av spesiell variasjon. Det er fordi man ønsker å minimere sjansen for å sette i gang tiltak uten å ha et godt grunnlag for det.
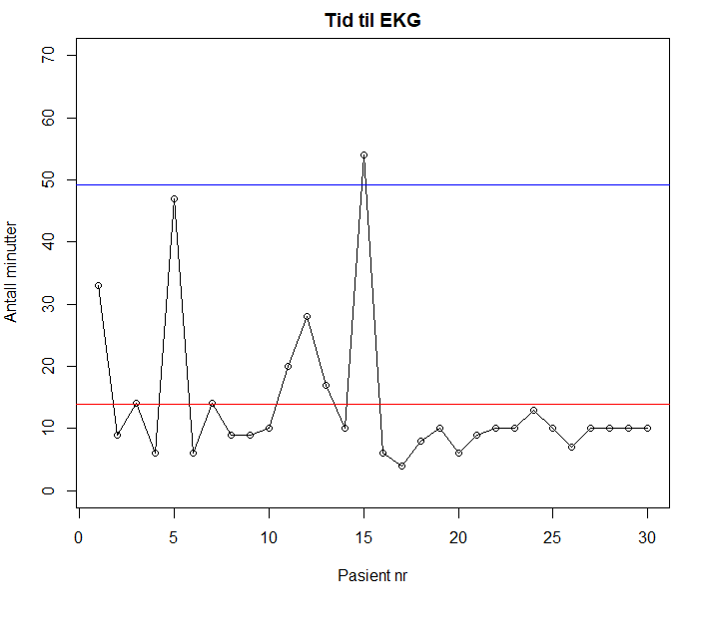
Figur 2 viser eksempel på kontrolldiagram med data fra Norsk hjerteinfarktregister. Hvert punkt representerer en pasient og viser tid fra ambulanse ankommer pasienten til EKG er tatt. Rød linje indikerer gjennomsnittet for de 30 pasientene, og blå linje angir 3 standardavvik fra gjennomsnittsverdien.
Tester for spesiell variasjon:
- Test 1 - Punkter utenfor kontrollgrensene: under normalfordeling er det kun 0.27 % sjanse for at et gitt punkt ligger utenfor kontrollgrensene ved normal variasjon, noe som derfor tyder på at det er spesiell variasjon som har generert dette datapunket.
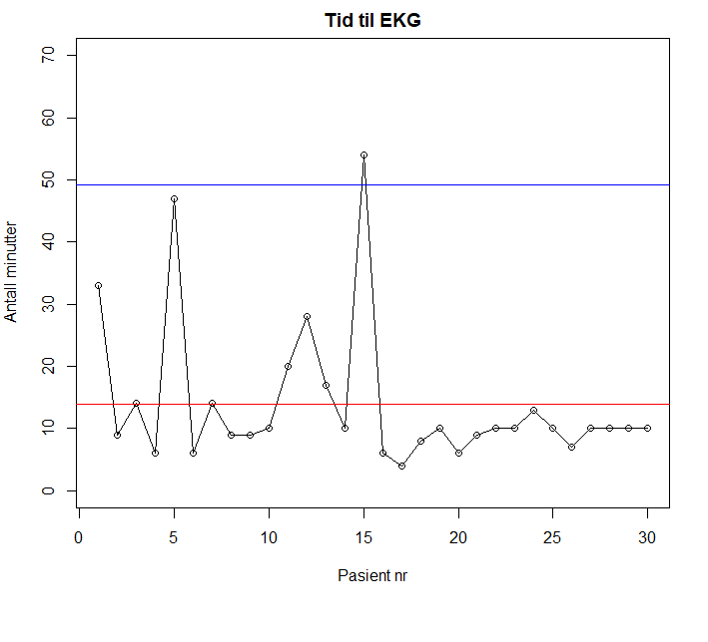
Figur 3 viser ett punkt utenfor kontrollgrensen (pasient 15), noe som indikerer spesiell variasjon bak dette datapunktet.
- Test 2 - Skifte i prosessen: 8 eller flere punkter etter hverandre på samme side av senterlinjen
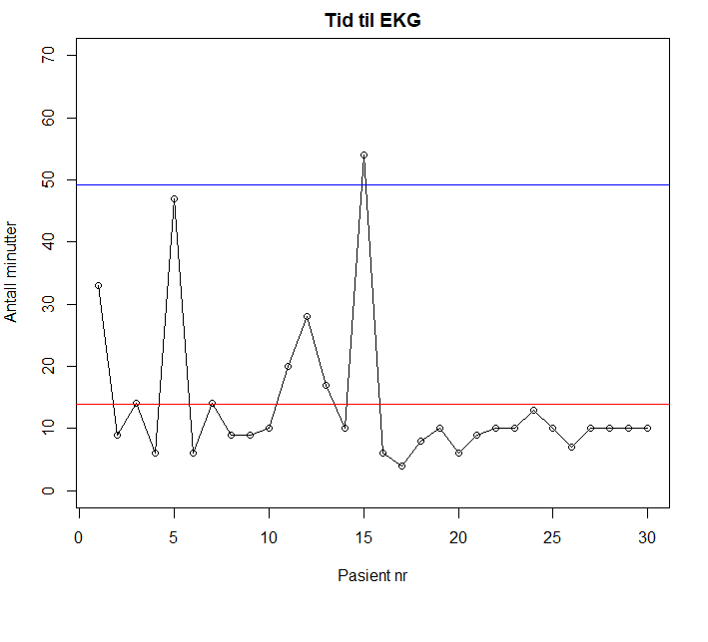
Figur 4 viser et kontrolldiagram fra Norsk hjerteinfarktregister med 15 påfølgende punkter på samme side av senterlinjen. Dette indikerer spesiell variasjon i prosessen (test 2).
- Test 3 - Trend: sammenhengende serie på 7 eller flere punkter av økende eller synkende verdier. Like verdier teller som ett punkt. Trender ser man bare sjelden i helsevesenet, og man tar med denne testen mest for å vise at det er mye som lett kan mistolkes som trender og som ikke er det.
Vanligvis vil disse tre testene være nok for å finne spesiell variasjon i helsevesenet, og være en balanse mellom det å finne falsk spesiell variasjon og det å gå glipp av spesiell variasjon. Det finnes likevel flere tester som er i bruk, og vi tar derfor med to av dem som brukes mye her:
- Test 4: 2 av 3 påfølgende punkter på samme side av senterlinjen og mer enn 2 standardavvik fra senterlinjen
- Test 5: 4 av 5 påfølgende punkter på samme side av senterlinjen og mer enn 1 standardavvik fra senterlinjen
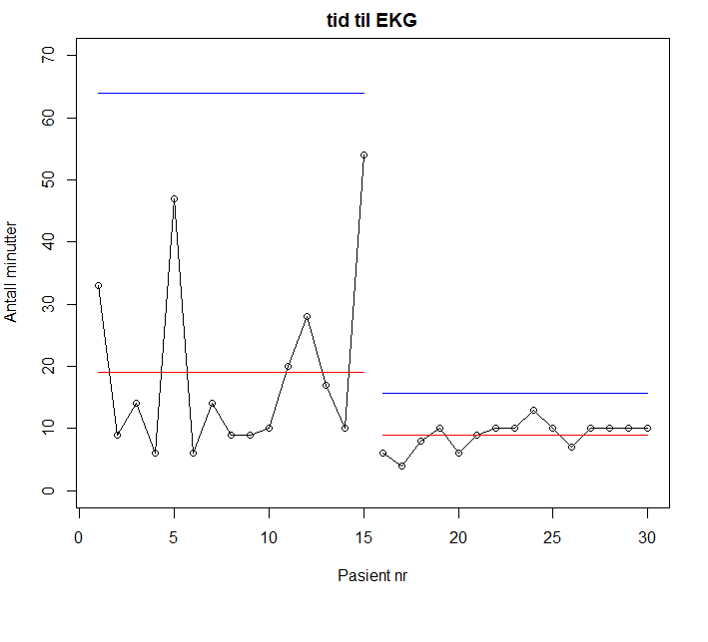
Figur 5 viser eksempel på bruk av kontrolldiagram i kvalitetsforbedringsprosjekter. Figuren viser tid fra ambulanse ankommer pasient til EKG er tatt. For de første 15 pasientene var gjennomsnittstiden 19 minutter, og for de siste 15 pasientene var gjennomsnittstiden 9 minutter. Innad i både den første og siste perioden var det kun naturlig variasjon (ingen punkter utenfor kontrollgrensen). Figuren viser at det var en reduksjon i tid til EKG tatt fra periode 1 til periode 2.
Det finnes mange ulike typer kontrolldiagrammer avhengig av hva slags data man har, vi presenterer noen av de vanligste her:
- I-diagram: for individuelle verdier. Passer best når hvert datapunkt består av kun én enkelt observasjon, for eksempel ventetid per pasient på legevakten. Kontrollgrensen er en rett linje, 3 standardavvik fra de individuelle verdiene sett under ett. Ta med noe om moving range- delen?
- P-diagram: for proporsjoner/prosenter. Passer best når dataene er andeler der teller ikke kan bli høyere enn nevner (maks 100 %) og passer derfor godt for registrenes kvalitetsindikatorer. Nevneren bør ikke være for liten, da øker faren for falske positive. Det er litt uenighet om hvor grensen til en for liten nevner går, noen mener 12 er nok, mens andre sier minst 25.
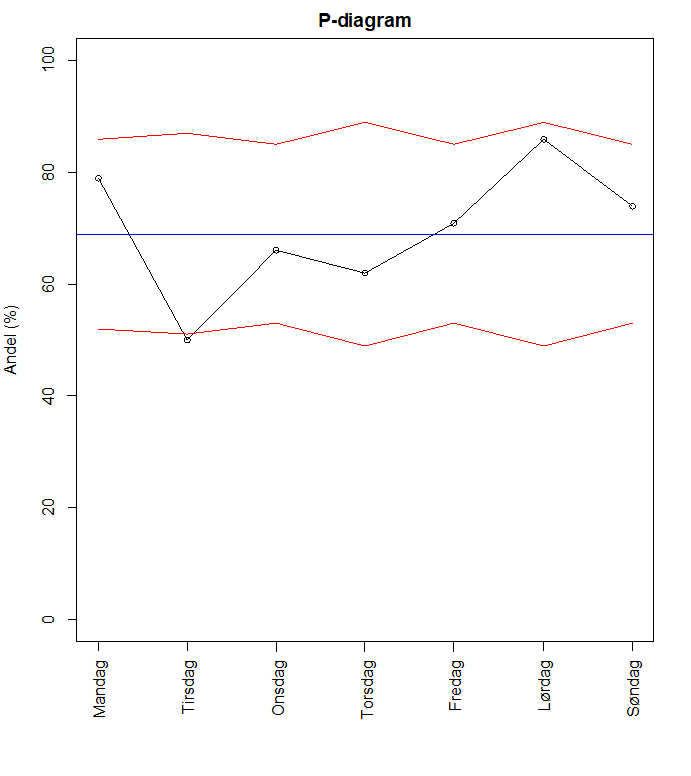
Figur 6 viser ett eksempel på P-diagram med data fra Norsk hjerneslagregister. Figuren viser andel pasienter der trombolyse blir gitt innen 40 minutter etter innleggelse i sykehus, fordelt etter ukedag. Punktene i figuren inkluderer ulikt antall pasienter, noe som fører til at kontrollgrensene varierer mellom ukedagene. Kontrollgrensene er basert på 3 standardavvik fra gjennomsnittsverdien over hele perioden, og tar hensyn til antall inkluderte pasienter for hver ukedag. For tirsdager viser figuren at andel pasienter som fikk trombolyse innen 40 minutt etter innleggelse var lavere enn nedre kontrollgrense, noe som indikerer spesiell variasjon i prosessen.
Kontrollgrensene vil variere avhengig av størrelsen på nevneren i hvert punkt. Legg inn formel?
• G-diagram: brukes for sjeldne hendelser, typisk uheldige hendelser. Noen hendelser er så sjeldne at det er vanskelig å få sikre prosentangivelser, noe som gjør det vanskelig bruke et p-diagram. I et g-diagram presenterer man derfor antall hendelser eller antall dager mellom de uheldige hendelsene.
Oppsummering run-diagram
Fordeler:
- Kan bruke samme plot på alle typer data (målte data, telte data, prosenter, forholdstall osv)
- Trenger færre punkter (minimum 15)
Ulemper:
- Kan ikke oppdage alle spesielle variasjoner
Oppsummering kontrolldiagram
Fordeler:
- Kan oppdage alle spesielle variasjoner
- Kan si hvilke grenser en stabil prosess vil holde seg innenfor
Ulemper:
- Krever flere datapunkter (20-30)
- Ulike typer plot for ulike datatyper
Kilde:
FHIs kompendium:
Kapittel 1 Grunnleggende konsepter og Run Chart (fhi.no)